Chain-of-thought reasoning has become the default mode for modern LLMs — models like o1, DeepSeek-R1, and QwQ produce long internal monologues before every answer. But this “always think” approach has a fundamental problem: for many real-world tasks, extended reasoning is not just unnecessary — it actively hurts. Formatting tasks, simple factual queries, social chitchat, and instruction-following prompts all suffer when the model wastes thousands of tokens second-guessing itself. The model overthinks, hedges, or introduces errors that wouldn’t exist in a direct answer.
We want a single model that handles both regimes gracefully: reason deeply when it genuinely helps (complex math, multi-step logic), and answer directly when thinking adds no value or even degrades quality. More importantly, we want the two modes to reinforce each other during training — the model’s experience in thinking mode teaches it what kinds of problems benefit from reasoning, while its no-think experience teaches it to be concise and decisive. The routing decision itself should be learned end-to-end, not delegated to an external classifier or a user-facing system prompt.
Our approach is built on a simple counterfactual question: “Would thinking have helped here?” For each training prompt, we run the model in both modes (forced-think and forced-no-think), compare the outcomes, and use the gap as a teaching signal. This paired counterfactual rollout provides clean, per-sample evidence of when reasoning adds value — no human labels, no heuristics, no difficulty classifiers needed. The model then gradually learns to make this decision autonomously, transitioning from full supervision to self-routing through a curriculum.
Our method has shown promising initial results: the self-routed model achieves accuracy comparable to always-thinking while choosing to think only ~50% of the time, yielding roughly 40% fewer tokens generated on the training distribution. Key technical challenges we solved include routing gradient delivery via advantage injection, vLLM V1 compatibility through a prefill+reorg trick, mode-balanced loss scaling to prevent gradient starvation, and a curriculum that prevents routing collapse. Everything runs on standard verl/GRPO with zero infrastructure modifications.
1. Motivation: The Compute-Quality Tradeoff
Modern reasoning models (o1, DeepSeek-R1, QwQ) achieve impressive results by generating long chains of thought before answering. But this comes at a steep cost:
- “What is 2+2?” → 2000 tokens of reasoning → “4”
- “Prove the Riemann Hypothesis for all non-trivial zeros…” → 2000 tokens of reasoning → useful
The problem is obvious: not every query deserves the same compute budget. Simple questions waste tokens (and latency and money) on unnecessary reasoning. Hard questions genuinely benefit from extended thinking.
Why existing solutions fall short
| Approach | Problem |
|---|---|
| System prompt (“think step by step”) | Static — can’t adapt per query |
| Router head (MLP classifier) | Requires architecture changes; binary decision loses gradient signal |
| Length penalty alone | Doesn’t distinguish “short because easy” from “short because lazy” |
| Two separate models (fast/slow) | Doubles serving cost; routing still needs a classifier |
Our desiderata
- Single model — one set of weights handles both modes
- Learned routing — the model itself decides, not a separate classifier
- End-to-end RL — routing quality improves alongside response quality
- Zero infrastructure changes — works with standard GRPO on verl
- Native tokens — uses the model’s existing
<think>/</think>vocabulary
2. Key Insight: Routing as First-Token Choice
Modern reasoning models already have native special tokens for thinking:
<think>: begins a reasoning block</think>: ends a reasoning block
The generation format is:
[Think mode] assistant: <think> ...reasoning... </think> answer
[No-think mode] assistant: </think> answer directly
The routing decision is entirely captured by the first generated token. If the model outputs <think> first, it enters reasoning mode. If it outputs </think> first, it skips reasoning and answers directly.
This means:
- No architecture changes needed (it’s just next-token prediction)
- The routing probability is
π(first_token | prompt)— fully differentiable - We can train this probability using standard policy gradient methods
3. Approach: Counterfactual Routing via Paired Rollouts
3.1 The Counterfactual Question
For each training prompt, we want to answer: “Would thinking have helped here?”
We answer this empirically by running two forced rollouts per sample:
- Think rollout (TH): Force the model to think → generate → get reward R_TH
- No-think rollout (NT): Force the model to skip thinking → generate → get reward R_NT
The utility gap = E[R_TH] - E[R_NT] tells us:
- Gap > 0: Thinking helps → encourage
<think> - Gap < 0: Thinking hurts (or wastes compute) → encourage
</think> - Gap ≈ 0: Doesn’t matter → default to no-think (save compute)
3.2 Three-Phase Curriculum
We don’t immediately let the model self-route. Instead, we use a curriculum that gradually transfers control:
Phase 1 (steps 0-50): 100% paired, 0% self-routed
Phase 2 (steps 50-150): 70% paired, 30% self-routed
Phase 3 (steps 150+): 30% paired, 70% self-routed
(minimum 15% paired always maintained)
Why?
- Phase 1: The model has no routing ability yet. 100% paired rollouts provide maximum supervision signal for the routing token.
- Phase 2: The model has started learning. We let it practice self-routing on 30% of samples while maintaining strong supervision.
- Phase 3: The model is competent. Mostly autonomous, with a minimum 15% paired to prevent router drift.
3.3 Per-Step Training Flow
batch (B samples)
├── paired (N_p samples) ──────────────────────────────────────
│ For each sample, run TWO forced rollouts:
│ ├── TH rollout: force <think> → generate K times → R_TH
│ └── NT rollout: force </think> → generate K times → R_NT
│
│ utility_gap = mean(R_TH) - mean(R_NT) - nothink_bias
│
│ For each mode batch (TH and NT separately):
│ ├── Standard GRPO: compute advantages for response quality
│ └── Overwrite advantage at position 0 with routing signal:
│ TH: adv[pos0] = +scale × tanh(utility_gap) × length_comp
│ NT: adv[pos0] = -scale × tanh(utility_gap) × length_comp
│ → Single actor update with modified advantages
│
└── self-routed (B - N_p samples) ─────────────────────────────
Model freely picks first token → standard GRPO (full response)
4. Technical Deep Dive
4.1 Advantage Injection (Not CE Loss)
The most critical design decision: how do we deliver the routing gradient?
Option A: Separate CE loss (rejected)
- Add a cross-entropy loss on the first-token logits with soft label from utility gap
- Problem: Requires modifying verl’s actor worker (remote Ray calls on distributed workers)
- Problem: Dual loss objectives can conflict
Option B: Advantage injection (chosen) ✓
- After GRPO computes content-quality advantages, overwrite the advantage at position 0 with the routing signal
- Produces the same REINFORCE gradient: $\nabla \propto \text{utility\_gap} \times \nabla\log \pi(\text{routing\_token} \mid \text{prompt})$
- Zero changes to verl core — everything flows through the standard advantages → actor_update pipeline
The routing gradient, unpacked:
$$\text{adv}[t_0] = \pm\, \text{scale} \cdot \tanh(\text{utility\_gap})$$After the standard policy gradient step:
$$\nabla_\theta \mathcal{L} \;\propto\; \text{adv}[t_0] \cdot \nabla_\theta \log \pi_\theta(\text{routing\_token} \mid \text{prompt})$$$$= \pm\, \text{scale} \cdot \tanh(\text{gap}) \cdot \nabla_\theta \log \pi_\theta(\text{tok} \mid \text{prompt})$$The tanh bounding ensures no single noisy sample can inject extreme gradients. The scale parameter (default 3.0) controls how strongly the routing signal competes with content gradients.
4.2 The Asymmetric No-Think Bias
A naive utility gap (R_TH - R_NT) is symmetric: when both modes produce the same reward, gap ≈ 0 and the router gets no signal. This causes the model to default to its pre-training prior — which typically strongly prefers <think>.
The nothink_bias breaks this symmetry:
adjusted_gap = raw_gap - nothink_bias
With nothink_bias = 0.1:
- Easy problem (both correct, gap ≈ 0): adjusted = -0.1 → favor no_think
- Hard problem (only TH correct, gap ≈ 0.7): adjusted = +0.6 → favor think
- Medium (TH slightly better, gap ≈ 0.2): adjusted = +0.1 → mild think preference
This implements the principle: “Default to no-think, only think when it CLEARLY helps.” The bias is a cost-of-thinking threshold.
4.3 Content-Only Utility Gap: Why We Removed Format & Length from the Reward
Early experiments revealed that including format reward and length penalty in the training signal caused two distinct and severe failure modes. We removed both entirely from the reward function.
Format reward → Reward hacking: The format reward checks structural patterns (<think>...</think>answer vs </think>answer). Since TH and NT responses have inherently different structures, the format score creates a spurious signal that the model learns to exploit. Instead of learning to produce correct answers, the model games the structural pattern — for example, generating empty think blocks or minimal content that still satisfies the format checker. This is classic reward hacking: the model optimizes the proxy (format) at the expense of the true objective (correctness).
Length penalty → No-think output collapse: The length penalty (-weight × tokens/max_len) doesn’t just bias the routing decision — it causes the no-think mode’s output quality to collapse. Here’s the mechanism: in GRPO, the length penalty becomes part of the per-sample reward that shapes the content advantage. For NT rollouts (which are already short, ~100 tokens), the penalty creates a gradient that pushes the model to generate even shorter outputs. This triggers a positive feedback loop: shorter → higher reward (less penalty) → even shorter → eventually the no-think mode collapses to outputting just a few tokens of nonsense. The mode cannot learn to produce good direct answers because “shorter = better” dominates the GRPO signal.
Solution: Use only the binary correctness score (0 or 1) — both for the routing utility gap AND for the GRPO response-quality training:
reward = content_score (binary: 0 or 1)
utility_gap = pass_rate_TH - pass_rate_NT - nothink_bias
This gives:
- Clean routing signal: “Does thinking actually help the model get the answer RIGHT?”
- Stable response learning: Both modes optimize purely for correctness, without length-based distortions. The no-think mode learns to give correct concise answers, not just short answers.
The compute savings from no-think emerge naturally: the model learns that short correct answers are achievable without thinking, and the nothink_bias provides the preference for efficiency. No explicit length penalty is needed.
4.4 Loss Aggregation and Mode-Balanced Scaling
When Think (2000 tokens) and No-Think (100 tokens) responses coexist in the same batch, the choice of loss aggregation strategy has a major impact on gradient balance between modes. This section explains the problem and our solution.
The Three Aggregation Strategies
1. token_mean (flat global average):
L = Σ(all tokens in batch) [adv_t × clip(ratio_t) × mask_t] / T_total
Every token in the batch shares one denominator. A TH response (2000 tokens) contributes ~95% of the gradient mass, NT (100 tokens) contributes ~5%. The routing token (pos0) for both modes is divided by the same T_total → routing gradients are symmetric. But for content learning, NT is starved.
2. seq_mean_token_mean (verl/GRPO default):
L = (1/N) Σ_seq [ (1/T_seq) Σ_t [adv_t × clip(ratio_t) × mask_t] ]
First compute a per-sequence token-mean, then average across sequences. Each sequence contributes equally to the batch loss regardless of length. This sounds fair — but it creates a severe asymmetry for thinking mode:
- TH routing token gradient ∝
adv_routing / 2000(diluted by its long sequence) - NT routing token gradient ∝
adv_routing / 100(concentrated in its short sequence) - Result: NT’s routing signal is 20× stronger than TH’s
The content tokens suffer even more: each content token in thinking mode gets 1/2000 of the per-sequence gradient budget, while each no-think content token gets 1/100. Thinking mode is systematically starved of gradient — both for routing and for content learning. The model quickly learns to avoid thinking because the gradient signal saying “thinking helped” is 20× weaker than the signal saying “not-thinking worked”.
3. seq_mean (per-sequence, no token normalization):
L = (1/N) Σ_seq [ Σ_t [adv_t × clip(ratio_t) × mask_t] ]
No per-token normalization within sequences. Longer sequences accumulate more gradient (proportional to length). This over-weights thinking mode — now TH dominates by 20×.
The Problem: No Strategy Is Balanced By Default
| Strategy | Routing gradient ratio (TH:NT) | Content gradient ratio (TH:NT) |
|---|---|---|
token_mean | 1:1 (symmetric) | 20:1 (TH dominates content) |
seq_mean_token_mean | 1:20 (NT dominates) | 1:20 (NT dominates) |
seq_mean | 20:1 (TH dominates) | 20:1 (TH dominates) |
None gives balanced gradients for both routing AND content simultaneously.
Our Solution: Mode-Balanced Scaling (content_length_power)
We use token_mean (which gives symmetric routing gradients) plus a mode-balanced content scaling that selectively compensates the content gradient imbalance:
# For content tokens only (not routing token at pos0):
content_weight[seq_i] = (T_seq_i) ^ (-content_length_power)
This gives a tunable spectrum:
content_length_power | TH content grad share | NT content grad share | Effect |
|---|---|---|---|
| 0.0 (token_mean) | 95% | 5% | NT content starved |
| 0.3 | ~85% | ~15% | Mild rebalancing |
| 0.5 | ~75% | ~25% | Moderate — square-root scaling |
| 1.0 (seq_mean_token_mean equiv.) | 50% | 50% | Equal per-mode, but dilutes TH per-token signal |
We use content_length_power = 0.5 as a compromise: it gives thinking mode enough per-token gradient to learn complex reasoning, while ensuring no-think mode still gets meaningful content gradient. Crucially, the routing token at pos0 is excluded from this reweighting — its gradient remains symmetric under the base token_mean.
Why not just use seq_mean_token_mean? Because it kills the routing learning: thinking mode’s routing token gets 20× less gradient, so the model never learns “thinking helps here”. The training collapses to always-nothink within a few hundred steps.
4.5 Prefill + Response Reorg (vLLM V1 Compatibility)
Problem: vLLM V1 does not support per-request logits processors.
Solution: The “prefill + reorg” trick:
Step 1: Append routing token to prompt
prompt_ids = [...original_prompt..., <think>] ← vLLM sees this as prompt
Step 2: Generate normally
vLLM generates: [content_token_1, content_token_2, ...]
Step 3: Reorg — move routing token from prompt to response
What trainer sees:
prompt = [...original_prompt...]
response = [<think>, content_token_1, content_token_2, ...]
Why this works: The actor’s forward pass computes log π(<think> | original_prompt) at position 0 — this IS the real routing probability. The advantage injection at pos0 directly creates a gradient on this probability. The dummy logprob from the agent loop is overwritten by _compute_old_log_prob.
4.6 Reward Function Design
The reward is pure binary correctness — no format score, no length penalty (see §4.3 for why these were removed).
reward = content_score (0 or 1)
Content Score (per data source)
- Math:
math_verify— symbolic equivalence checking - Instruction Following: Code execution verification
- Competition Math: Exact integer match
- Fallback: ROUGE-L similarity
The think block (<think>...</think>) is stripped before evaluation — only the final answer after </think> is scored.
4.7 Mixed Data: Why Diversity Matters
Training uses heterogeneous data sources:
- Math (~70%): problems that genuinely benefit from reasoning
- Instruction Following (~30%): formatting tasks where thinking is unnecessary
Why this matters: If all training tasks favor thinking, the router collapses to always-think (since there’s no negative signal). IF tasks provide the critical “no-think is correct AND faster” examples that teach the router to skip thinking on simple tasks.
The AdaptiveThinkDataset handles heterogeneous schemas using the _MultiDatasetView pattern — each file stays as a separate HF Dataset with its own Arrow schema. Bisect-based index lookup provides O(log n) access without any schema merging.
Preliminary Results: Routing Learns to Be Selective
Our method has achieved promising initial results. The metrics below are training reward (pass rate on the training distribution), which clearly demonstrate that the routing behavior emerges correctly — the self-routed model tracks the always-think accuracy closely, while choosing to think only ~48% of the time.
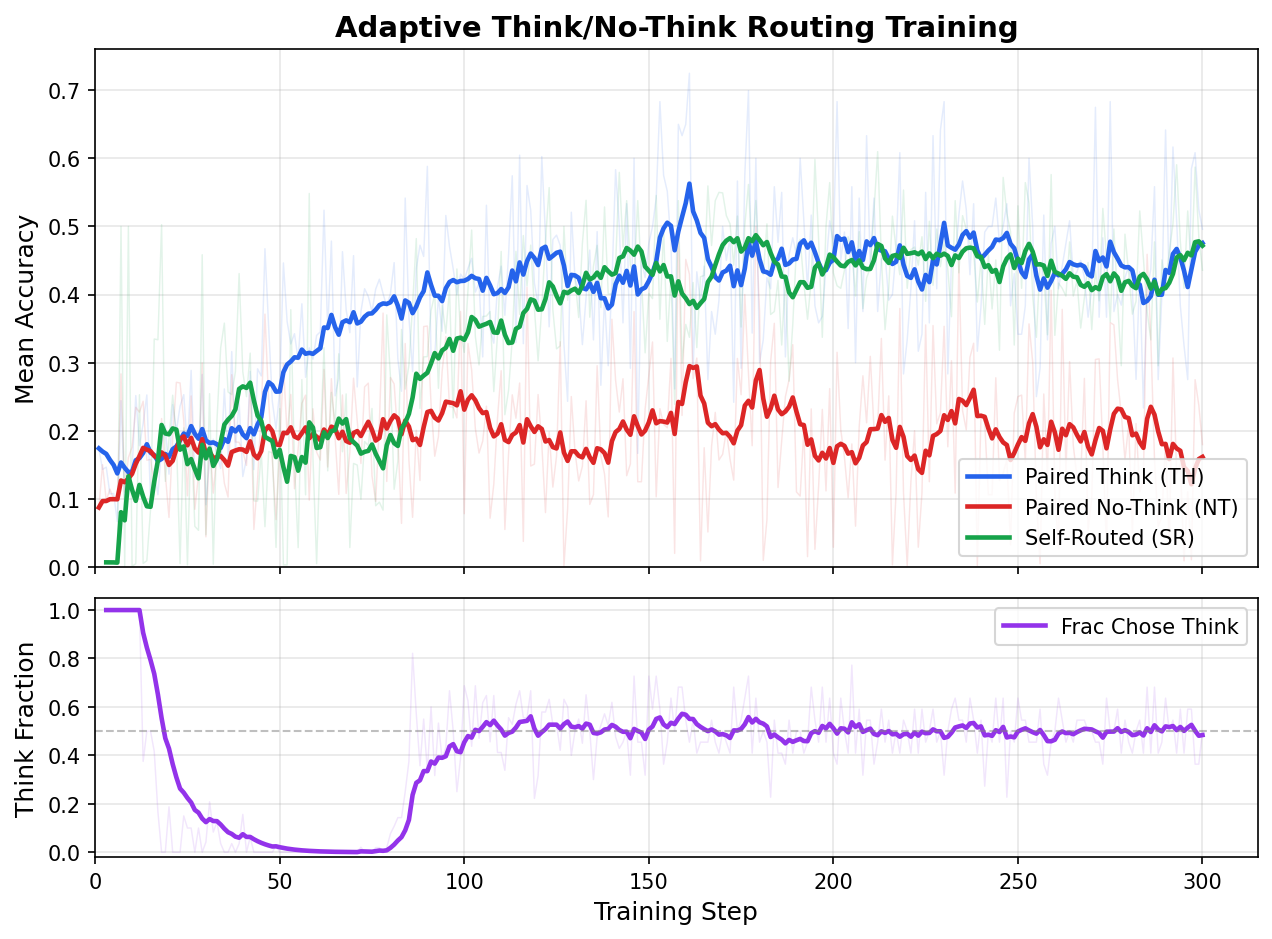 Figure: (Top) Mean accuracy for paired Think (TH), paired No-Think (NT), and Self-Routed (SR) rollouts over 300 training steps. SR accuracy tracks the Think oracle closely at ~0.47 despite selecting think only half the time. (Bottom) The model’s autonomous think fraction drops from 100% → ~48% as training progresses, demonstrating that the router learns to skip thinking on easy problems (IF tasks) while preserving it for hard ones (math).
Figure: (Top) Mean accuracy for paired Think (TH), paired No-Think (NT), and Self-Routed (SR) rollouts over 300 training steps. SR accuracy tracks the Think oracle closely at ~0.47 despite selecting think only half the time. (Bottom) The model’s autonomous think fraction drops from 100% → ~48% as training progresses, demonstrating that the router learns to skip thinking on easy problems (IF tasks) while preserving it for hard ones (math).
This validates the core hypothesis: with a balanced data mix providing clear “think helps” (math) and “think is unnecessary” (IF) examples, the model discovers an efficient routing policy that saves ~50% of thinking compute with negligible accuracy loss.
The response length plot further confirms the compute savings:
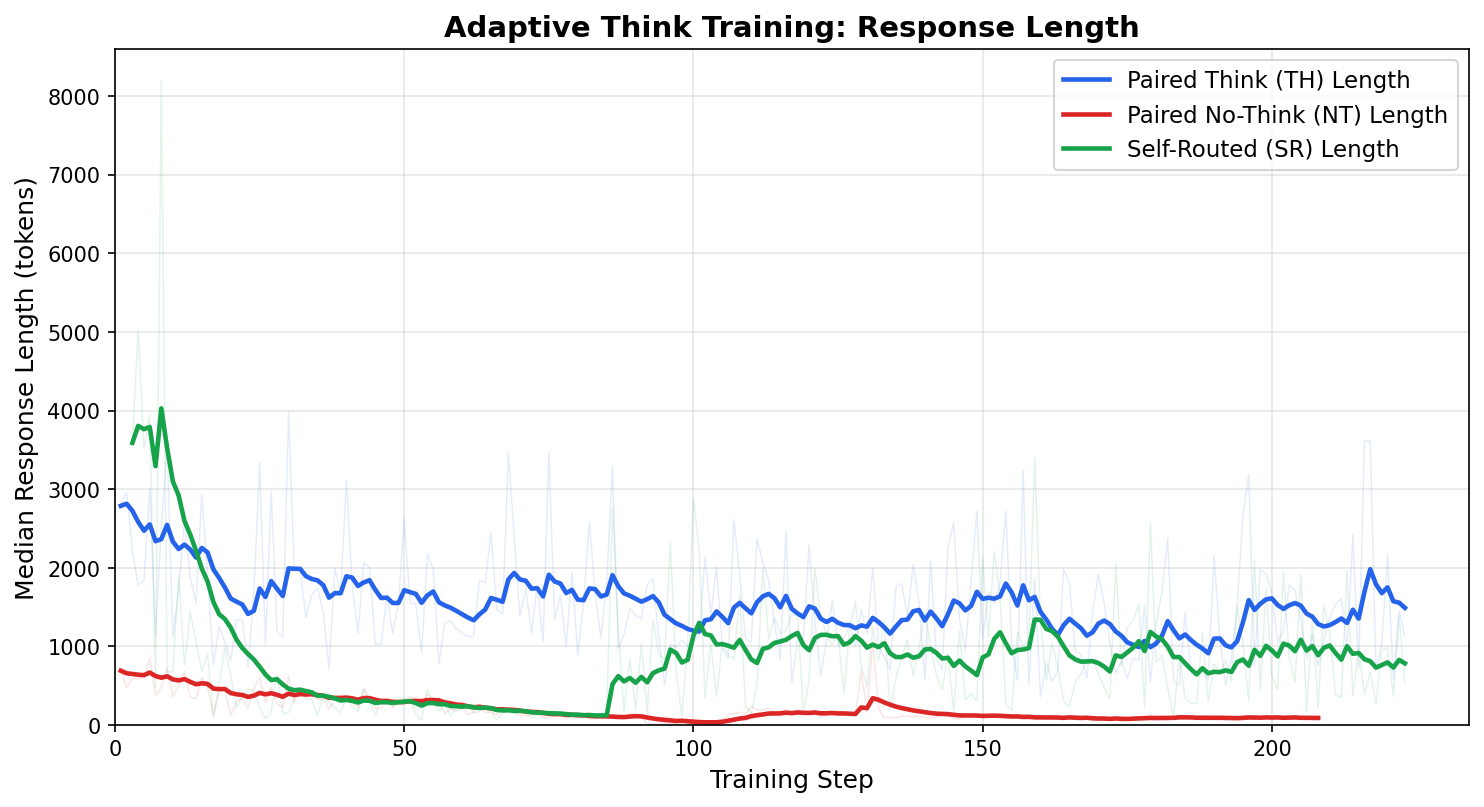 Figure: Median response length (tokens) over training. The self-routed model (green) produces responses roughly half the length of always-think (blue), confirming substantial inference compute savings while maintaining near-identical accuracy.
Figure: Median response length (tokens) over training. The self-routed model (green) produces responses roughly half the length of always-think (blue), confirming substantial inference compute savings while maintaining near-identical accuracy.
At step 200, a quantitative snapshot:
| Metric | Always-Think (TH) | Self-Routed (SR) | Δ |
|---|---|---|---|
| Mean Accuracy | 0.451 | 0.455 | +0.4pp (SR slightly higher) |
| Median Response Length | 1611 tokens | 949 tokens | −41% |
| Think Fraction | 100% | 51% | — |
The self-routed model achieves equivalent (even marginally better) accuracy while generating 41% fewer tokens on average, by choosing to think on only ~51% of queries. This confirms the core value proposition: near-oracle accuracy at roughly half the inference compute.
4.8 Dynamic Sampling (Filtering Dead Prompts)
Not all prompts provide useful gradient signal. A prompt where all K rollouts produce identical rewards (std = 0) generates zero advantage → zero gradient. These “dead” prompts waste compute.
For paired batches, the definition of “alive” is nuanced:
- A prompt has routing signal if |utility_gap| > 0 (even if within-mode std = 0)
- Example: TH = [1,1,1,1], NT = [0,0,0,0] → gap = 1.0 (strongest routing signal!)
- A prompt has content signal if at least one mode has within-mode variance
A prompt is truly dead only if: gap ≈ 0 AND both TH std = 0 AND NT std = 0.
5. Comparison to Related Work
| Method | Routing mechanism | Training signal | Infra changes |
|---|---|---|---|
| Ours | First-token choice | Counterfactual utility gap via RL | None (advantage injection) |
| System-prompt think mode | System prompt | None (user decides) | None |
| DeepSeek-R1 | Always thinks | Standard RL | None |
| Mixture-of-Depths | Learned skip layers | Auxiliary capacity loss | Architecture change |
| Speculative decoding | Draft model routing | Acceptance probability | Separate model |
| Router MLP | Classifier head | Supervised (labeled difficulty) | Architecture + labels |
Key differentiators:
- End-to-end: The router is part of the policy, trained by the same RL objective
- No labels needed: Utility gap is computed from rollout rewards, not human labels
- No architecture changes: Uses existing vocabulary tokens
- Curriculum prevents collapse: Gradual transition from supervised to autonomous
Where we sit in the landscape
The “efficient reasoning” literature is booming, but existing work clusters into two camps:
Camp 1: Continuous budget control — These papers ask “how many tokens should the model spend?” and control reasoning length rather than making a discrete mode decision. Curriculum-Aware Budget Scheduling assigns per-query token budgets; Leash uses adaptive length penalties; S1 budget forcing inserts <wait> tokens; The Art of Efficient Reasoning surveys the space. These approaches operate on a continuous axis (token count) and are best suited for tasks that all require some reasoning but at varying depths (e.g., easy math → hard math). They don’t address the more fundamental question of whether to reason at all — a critical distinction when the task mix includes both reasoning-heavy tasks and simple tasks (formatting, chitchat) where any thinking degrades quality.
Camp 2: Manual or external routing — Several models support both think and no-think modes, but the routing decision is not learned end-to-end. Qwen3 and DeepSeek-R1 offer mode switching via system prompts — the user manually chooses. To Think or Not To Think empirically studies when thinking helps/hurts but proposes no training method. Trade-offs in Large Reasoning Models analyzes the tradeoffs without learning a router. The fundamental limitation: the model never learns when to think — it relies on an oracle (human or external classifier) at inference time.
Concurrent work: Large Hybrid-Reasoning Models (LHRMs) — LHRMs is the most closely related concurrent work. They also do paired rollouts (forced Think + forced No-Think per query) and separate the training signal into inter-group (routing) and intra-group (content quality) advantages, combined as A = A_intra + α × A_inter. Key differences from our approach:
| Dimension | LHRMs (HGPO) | Ours |
|---|---|---|
| Routing signal | Binary (which mode’s mean reward is higher) | Continuous tanh(utility_gap) |
| Signal delivery | Additive (A_intra + α × A_inter) | Overwrite (pos0 purely routing) |
| Cold start | Requires 1.7M SFT (Hybrid Fine-Tuning) | No SFT needed (curriculum replaces it) |
| Self-routing practice | None during training (always forced) | Curriculum introduces self-routed batches |
| Reward source | Reward model (continuous scores) | Binary correctness (0/1) |
| Routing bounding | GRPO normalization on binary rewards | Explicit tanh + adaptive scale |
The core philosophical difference: LHRMs use additive advantages where routing and content signals mix at pos0, and their binary r_inter loses magnitude information (a gap of 0.01 and 0.9 give the same signal). We use advantage overwrite for clean separation and continuous tanh(gap) to preserve signal magnitude. Our curriculum also lets the model practice autonomous routing during training, rather than only experiencing forced modes.
Our contribution: (a) treats the think/no-think decision as a discrete, learned routing action within the model itself, (b) trains it end-to-end via RL using continuous counterfactual utility gap that preserves signal magnitude, (c) uses advantage overwrite for clean routing/content gradient separation, (d) introduces a curriculum that transitions from supervised paired rollouts to autonomous self-routing, and (e) requires zero infrastructure changes — no architecture modifications, no SFT cold start, no separate classifier, no length penalties.
6. Open Questions & Future Directions
Multi-level thinking: Beyond binary think/no-think, can we learn how much to think? Recent work suggests yes — Curriculum-Aware Budget Scheduling assigns per-query token budgets via curriculum learning to avoid both overthinking and underthinking; Adaptive Thinking Budgets extends this to multi-turn settings where different turns need different reasoning depths; and Leash uses adaptive length penalties with reward shaping to control reasoning length without collapsing quality. Our binary routing could naturally extend to a 3-way choice (no-think / short-think / long-think) by adding a third routing token.
Per-step budget & early exit: Can the model learn to stop thinking mid-reasoning? The Art of Efficient Reasoning surveys multiple approaches including distillation, reward design, and optimization tricks for controlling reasoning length. The S1 “budget forcing” approach inserts
<wait>tokens to extend or truncate reasoning at test time. An intriguing extension of our method would be to inject multiple “continue/stop” routing decisions at intermediate positions rather than only at pos0.Generalization to new domains: To Think or Not To Think tests reasoning models on Theory-of-Mind tasks, finding that thinking sometimes hurts performance on social reasoning — the model “overthinks” and second-guesses correct intuitions. This suggests the optimal routing policy is highly domain-dependent. Our utility-gap approach should generalize (the counterfactual rollout discovers what helps), but whether a router trained on math+IF transfers to creative writing or social tasks remains open.
Interaction with tool use: When the model has access to tools (code execution, search), the compute tradeoff shifts: thinking may be replaceable by tool calls. DOVA explores multi-agent orchestration where different agents handle different reasoning modalities. Our routing framework could extend to a 3-way decision: think / no-think / use-tool, with the utility gap computed across all three modes.
Scaling laws: How does the optimal think ratio change with model size? Recent technical reports hint that larger models need less explicit CoT for easier tasks. If the no-think mode’s direct-answer capability scales faster with parameters than the reasoning mode’s accuracy improvement, larger models should route more aggressively toward no-think — making adaptive routing even more compute-efficient at scale.
Appendix A: FAQ
Q: Why not just add a router head (MLP classifier)?
A: Three reasons:
- Requires model architecture modification → deployment complexity
- Binary classifier loses gradient signal (hard decision boundary)
- First-token routing is already a “soft classifier” via the full vocabulary distribution, with richer gradient signal
Q: Why tanh bounding instead of raw utility gap?
A: Without bounding, a single outlier sample (e.g., gap = 10.0 due to reward noise) would dominate the routing gradient for the entire batch. tanh compresses the signal to [-1, 1] before scaling, making training stable.
Q: Why separate GRPO for TH and NT (not mixed)?
A: Response lengths differ 10-20× between modes. Mixing them in one GRPO group would cause:
- Advantage normalization dominated by longer sequences
- Mean reward conflating fundamentally different distributions
- KL divergence computation becoming meaningless
Q: What happens if the model’s routing disagrees with the utility gap?
A: This is expected and healthy! The utility gap comes from forced rollouts with the CURRENT policy. As the model improves at thinking (or at direct answering), the utility gap naturally shifts. The router adapts continuously.
Q: Can this work with models that don’t have <think>/</think> tokens?
A: Yes — any two tokens can serve as routing tokens (configurable in YAML). The key requirement is that each token encodes to a single token ID. You’d need to add them to the tokenizer as special tokens and do minimal SFT to teach the model the generation format.
Appendix B: Mathematical Derivation of Routing Gradient
Under standard policy gradient (REINFORCE with baseline):
$$\nabla_\theta J = \mathbb{E}\left[\sum_t A(s_t, a_t) \cdot \nabla_\theta \log \pi_\theta(a_t \mid s_t)\right]$$For the routing token at position 0:
$$\nabla_\theta J_{\text{routing}} = \mathbb{E}\left[A(s_0, a_0) \cdot \nabla_\theta \log \pi_\theta(a_0 \mid \text{prompt})\right]$$We set $A(s_0, a_0)$ via advantage injection:
$$A(s_0,\; \langle\texttt{think}\rangle) = +\text{scale} \cdot \tanh(\text{utility\_gap})$$$$A(s_0,\; \langle\texttt{/think}\rangle) = -\text{scale} \cdot \tanh(\text{utility\_gap})$$The gradient pushes:
- $\log \pi(\langle\texttt{think}\rangle \mid \text{prompt})$ UP when utility_gap > 0 (thinking helps)
- $\log \pi(\langle\texttt{/think}\rangle \mid \text{prompt})$ UP when utility_gap < 0 (thinking doesn’t help)
Since these are the only two choices constrained at pos0, increasing one decreases the other. The magnitude of the push is proportional to |tanh(gap)| — stronger signal for clearer cases, weaker for ambiguous ones.